
Classifying and Extracting Data using Amazon Textract
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
In this blog, we will review how Mortgage Loan data can be extracted and classified using Amazon Textract.
Mortgage loan applications, typically consist of so many pages of various documentation. All of these papers must be classified and the data on each form retrieved before applications can be assessed. This isn't as simple as it seems! Aside from having various data structures in each document, the same data piece may have multiple names on different papers, such as SSN, Social Security Number, or Tax ID. These three all refer to the same piece of information.
Summary
Amazon Textract has an Analyze Lending API for evaluating and categorizing the documents contained in mortgage loan application packages, as well as extracting the data they contain. The new API can assist in processing applications quicker and with minimal errors, therefore improving the end-customer experience and lowering operational costs.
The API also can identify signatures and determine which papers have signatures and which do not. It also generates a summary of the papers in a mortgage application package and highlights significant documents such as bank statements. A set of machine learning (ML) models powers the new workflow. When the mortgage application package is uploaded, the workflow identifies the documents in the package before sending them to the appropriate ML model for data extraction depending on their categorization.
Amazon Textract Demo
Although the new API is meant for lenders to use in their business process workflows and apps, anybody may test it out using the Amazon Textract interface. This allows you to examine how the API categorizes documents and extracts the data items included inside them.
- Open the Amazon Textract console: The list of supported regions will be displayed to choose your preferred region.


2. Expand the Analyze Lending option and select the demo

The demo console immediately analyzes a set of test files, and the result of the output is shown above.
In the console, it displays that one document has a signature, showing that a signature was detected on page 2. 2
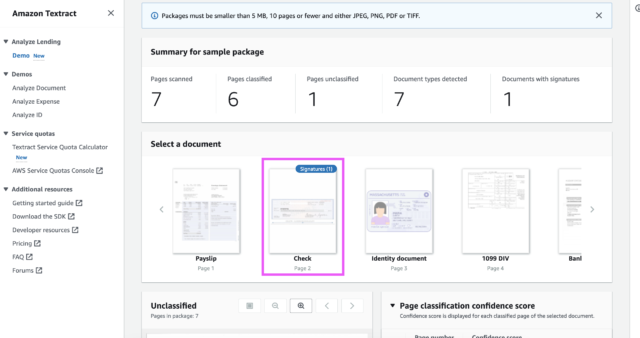
It indicates that it is a check with a signature. Because signature detection is a time-consuming operation, having the document automatically labeled when one is identified saves a substantial amount of time.

Also, a document is labeled Unclassified, because the document type could not be classified

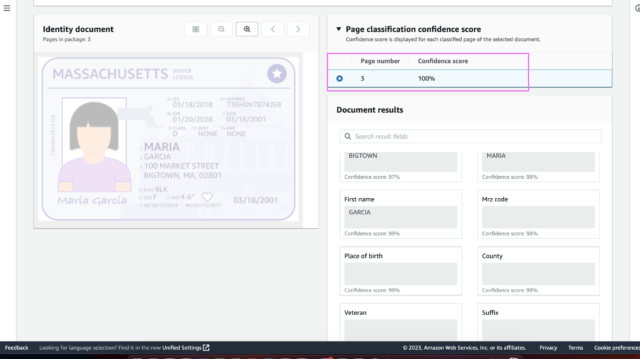
The identity document of the customer is also crucial for documentation, It shows a confidence score of 100%. The identity document information is displayed with each confidence score respectively.
Conclusion
Until recently, classification and extraction of data from mortgage loan application data were labor-intensive activities, however, some adopted a hybrid approach, including technology such as Amazon Textract. Customers.









